Dr. Andrew Gilbert
Exploring the intersection of AI, creativity, and human-centered design
Centre for Creative Arts and Technologies Department of Music and Media, Faculty of Arts and Social Sciences, University of Surrey
LinkedIn Email GitHub Google Scholar
Biography PhD Students Contact Me Research Updates Gilbertine Weekend Away Publications


Biography of Dr. Andrew Gilbert - Machine Learning and AI Research
Dr Andrew Gilbert is an Associate Professor in Machine Learning at the University of Surrey, where he co-leads the interdisciplinary Centre for Creative Arts and Technologies (C-CATS). His research lies at the intersection of computer vision, generative modelling, and multimodal learning, with a particular focus on building interpretable and human-centred AI systems. His work aims to develop machines that not only see and recognise the world, but also understand and creatively respond to it.
Dr Gilbert has made significant contributions to the fields of video understanding, , long-form video captioning, visual style modelling, and AI-driven story understanding. A distinctive feature of his research is its integration into the creative industries, applying technical advances to domains such as media production, performance capture, and digital arts. From training models to classify genre from movie trailers to designing systems that can generate synthetic images and narrative content, his work consistently pushes the boundaries of how AI can support and enhance human creativity.
He leads a vibrant and diverse team of PhD students, collaborating on cutting-edge projects in areas such as self-supervised learning from video, video diffusion models, and multimodal scene understanding. Many of these projects are conducted in close partnership with creative practitioners, industry partners, and other academic disciplines, reflecting Dr Gilbert’s commitment to interdisciplinary and impact-driven research.
In addition to his research leadership, Dr Gilbert is an active contributor to the UK computer vision community. He serves on the British Machine Vision Association (BMVA) Executive Committee, where he organises national technical meetings to foster collaboration between academia and industry. Through this work, he helps shape the research agenda for future AI systems that are explainable, responsible, and aligned with human values.
Key Achievements
- Co-leads the interdisciplinary Centre for Creative Arts and Technologies (C-CATS).
- Published over 100 research papers in top-tier conferences and journals.
- Best Paper Award at CVMP 2023 for DECORAIT.
- Active contributor to the British Machine Vision Association (BMVA).
PhD Students
I’m always looking for good PhD candidates, but normally, when I have funding available, it is for UK students. This is sometimes due to restrictions on the funding, but more often than not, it has more to do with the difference between home and overseas fees. However, if you are an exceptional candidate, email me. I am happy to work with high-calibre candidates to obtain scholarships either internally or from external funders such as the China Scholarship Council or the Commonwealth Scholarship Council.
Contact Me
Interested in collaborating or pursuing a PhD? Email me to discuss opportunities.
Featured Projects
Multitwine: Multi-Object Compositing with Text and Layout Control
A groundbreaking project enabling AI-driven compositing with precise text and layout control.
DANTE-AD: Dual-Vision Attention Network for Long-Term Audio Description
A novel approach to long-term video captioning using dual-vision attention networks.
Current PhD Students
- Irene Muñoz López - AI-Driven Adaptive Audio-Description Generation for Dynamic Inclusion in Immersive Media 2024
- Will Binnings - Quality of Experience Centred, Machine Learning Powered Rule Understanding for Inclusive Board Gaming 2025
- Oberon Buckingham-West - Adaptive Game Engines for Personalised Learning 2024
- Adrienne Deganutti - Long Term Video Captioning 2023
- Xu Dong - Group Activity Recognition in Video 2023
- Sadegh Rahmani - Human Inspired Video Understanding 2023
- Kar Balan - Decentralized virtual content Understanding for Blockchain- 2021
- Tony Orme - Temporal Prediction of IP packets in network switches - 2019
Alumi
- Mona Ahmadian - Self-Supervised Audio Visual Video Understanding 2022
- Katharina Botel-Azzinnaro - No Anchor, No Trust: Inference Journalism and the Empathy–Ethics Paradox in AI Nonfiction 2021
- Gemma Canet Tarrés - Levering Multimodality for Controllable Image Generation 2021
- Soon Yau - Text to Storyboard generation - 2021
- Ed Fish - Advancing Efficiency and Accessibility in Multimodal Video Understanding with Deep Learning - 2019
- Dan Ruta - Exploring and understanding fine-grained style - 2019
- Violeta Menendez Gonzalez - Novel viewpoint and stereo inpainting - 2019
- Kary Ho 2019
- Mat Trumble - 2015
- Phil Krejov - 2012
- Segun Oshin - 2008

Gilbertine Weekend Away
Working together is crucial for my lab and PhD student, so we go on a yearly trip away


Publications
2026
Generative Data Augmentation for Skeleton Action Recognition
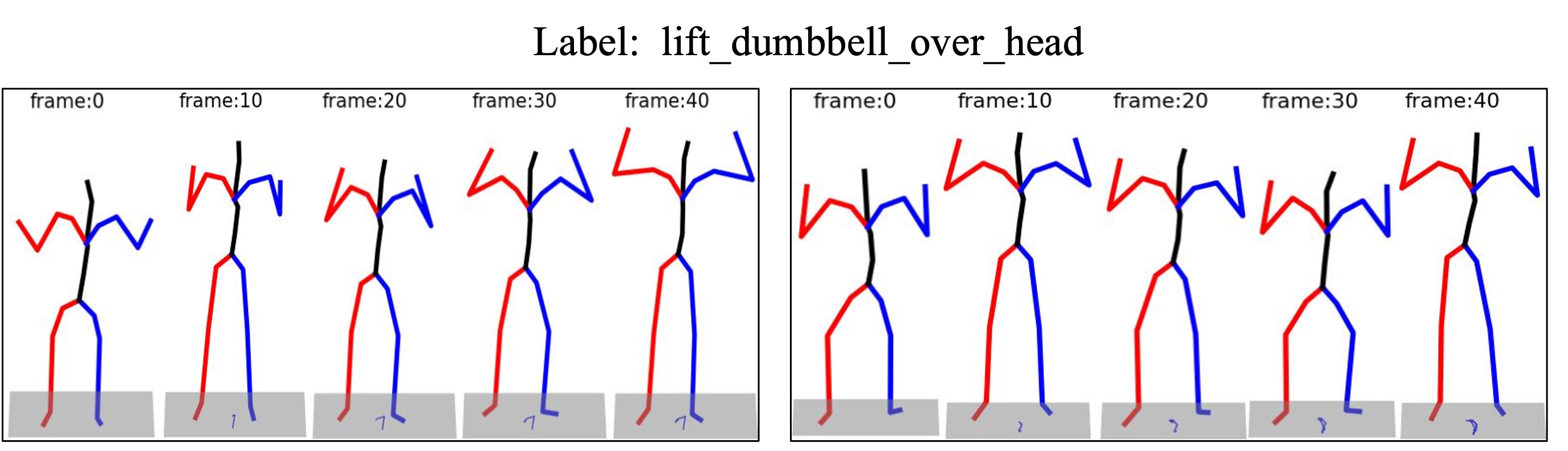
Xu Dong, Wanqing Li, Anthony Adeyemi-Ejeye, Andrew Gilbert, 20th IEEE International Conference on Automatic Face and Gesture Recognition FG’26, 2026
Early TCP Flow Length Regression with Machine Learning
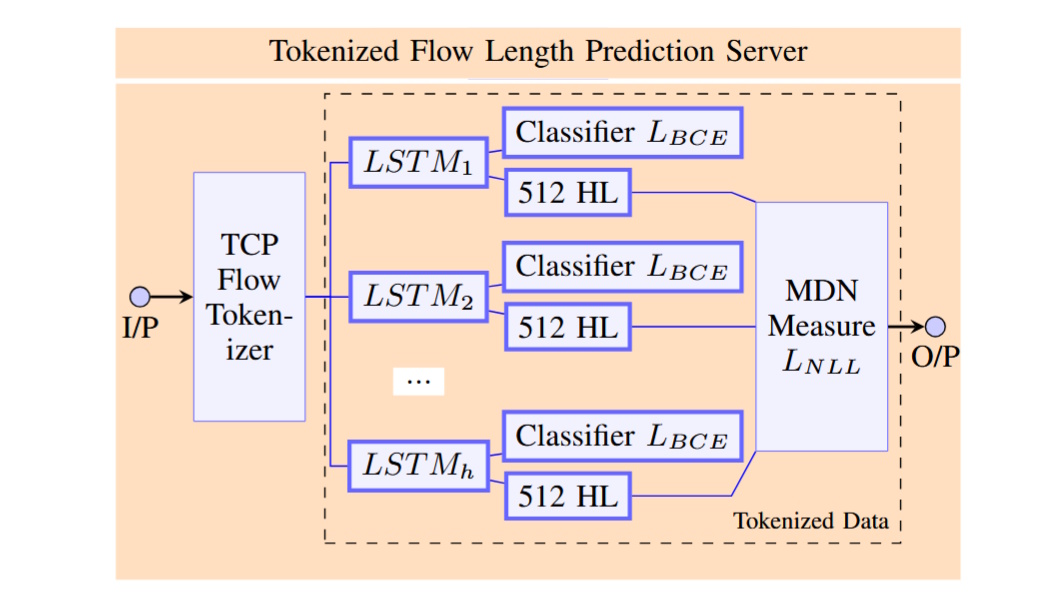
Anthony Orme, Anthony Adeyemi-Ejeye, Andrew Gilbert, IEEE Wireless Communications and Networking Conference (WCNC), Track 4: Emerging Technologies, Network Architectures, and Applications, 2026
Intelligent Video Understanding: Self-Supervised and Multimodal Learning

Mona Ahmadian, Thesis, 2026
No Anchor, No Trust: Inference Journalism and the Empathy–Ethics Paradox in AI Nonfiction
Katharina Botel-Azzinnaro, Thesis, 2026
Camera Tracking Systems and their Democratisation
![]()
Irene Muñoz López, Andrew Gilbert SMPTE Motion Imaging Journal, 2026
2025
UIL-AQA: Uncertainty-aware Clip-level Interpretable Action Quality Assessment
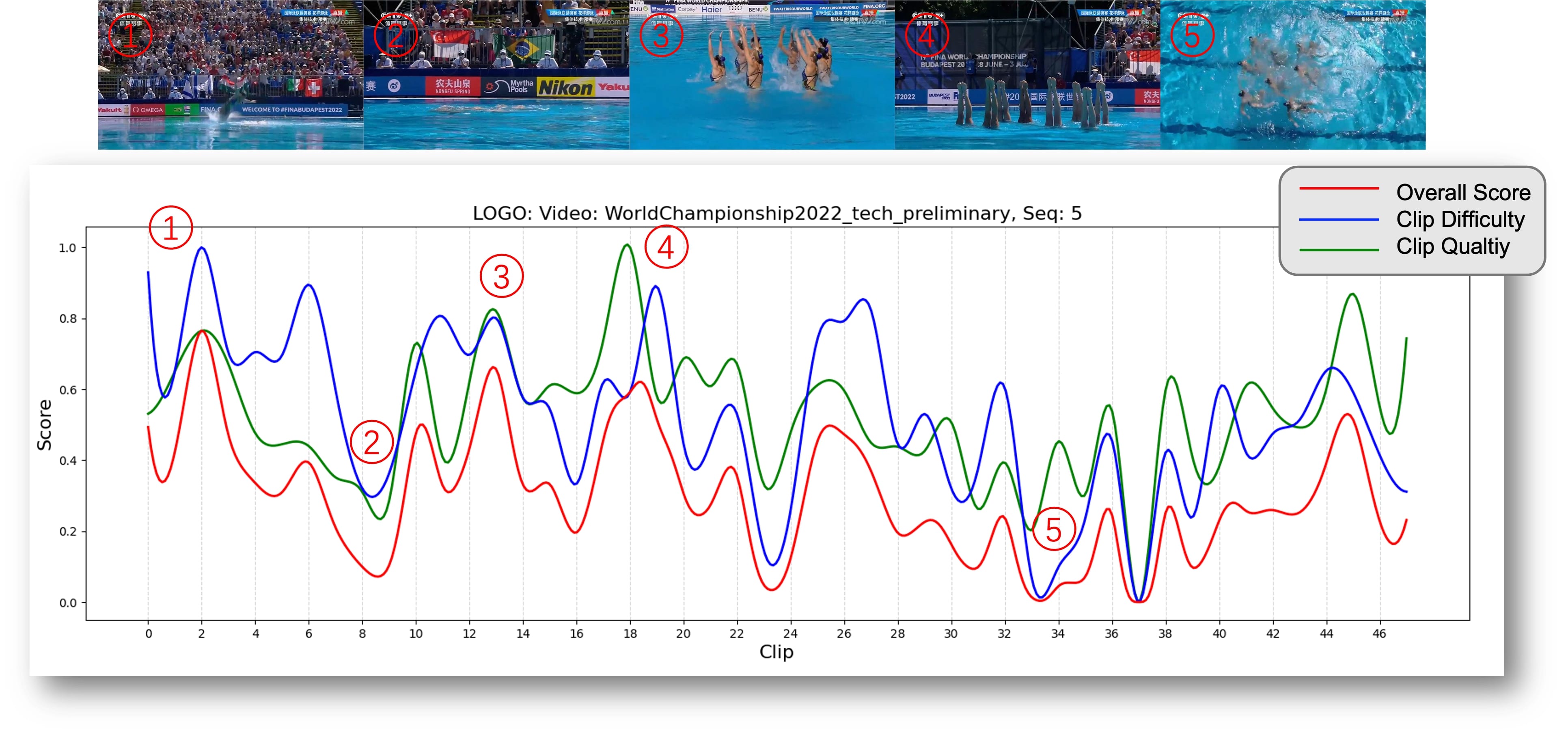
Xu Dong, Xinran Liu, Wanqing Li, Anthony Adeyemi-Ejeye, Andrew Gilbert, International Journal of Computer Vision (IJCV), 2025
Boosting Camera Motion Control for Video Diffusion Transformers
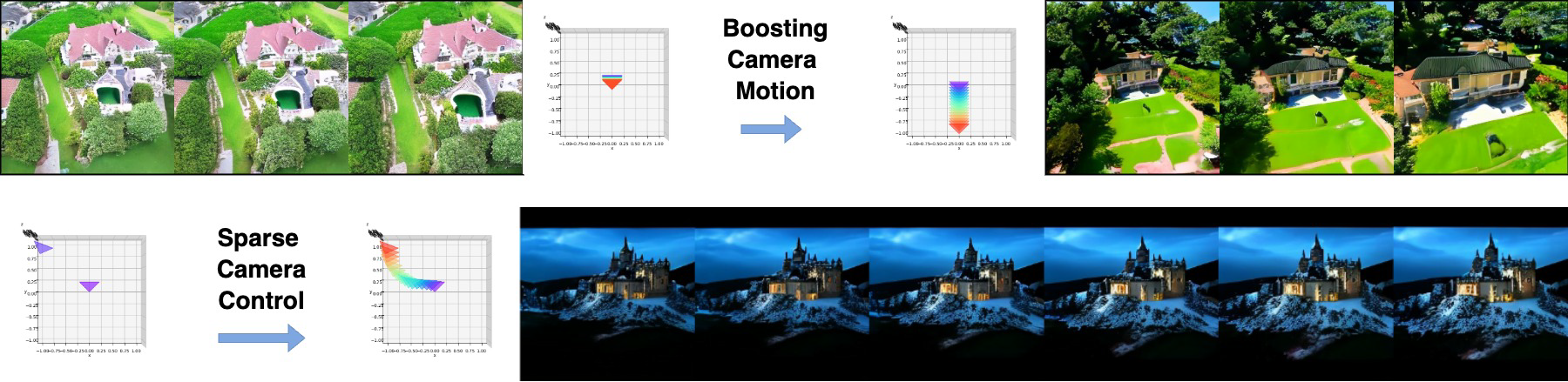
Soon Yau Cheong, Duygu Ceylan, Armin Mustafa, Andrew Gilbert, Chun-Hao Paul Huang, The 36th British Machine Vision Conference (BMVC’25) 2025
MultiNeRF: Multiple Watermark Embedding for Neural Radiance Fields
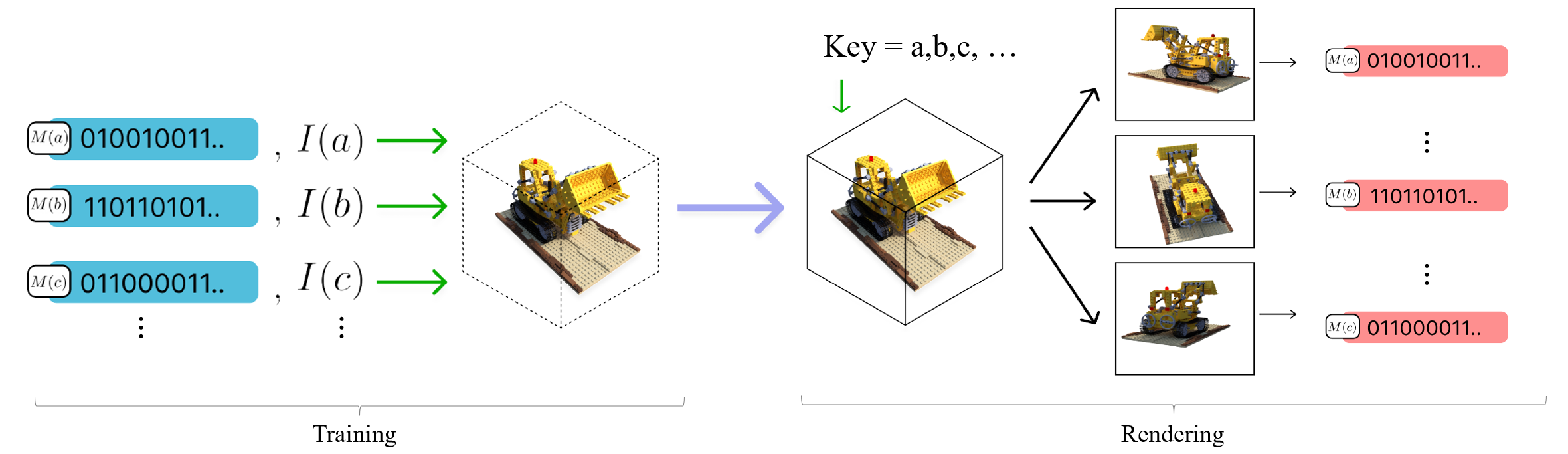
Yash Kulthe, Andrew Gilbert, John Collomosse, International Confernce on Computer Vision (ICCV’25) - The 1st Workshop on Authenticity & Provenance in the age of Generative AI (APAI’25), 2025
PLOT-TAL–Prompt Learning with Optimal Transport for Few-Shot Temporal Action Localization
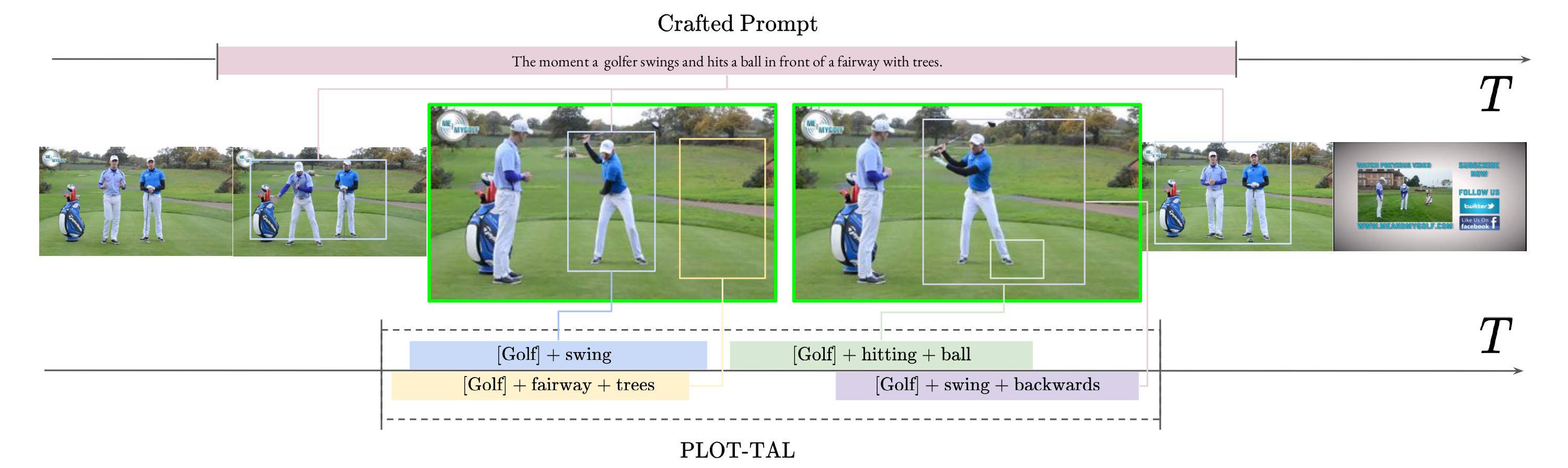
Ed Fish, Andrew Gilbert, International Confernce on Computer Vision (ICCV’25) - 6th Workshop on Closing the loop between Vision and Language, 2025
DEL: Dense Event Localization for Multi-modal Audio-Visual Understanding
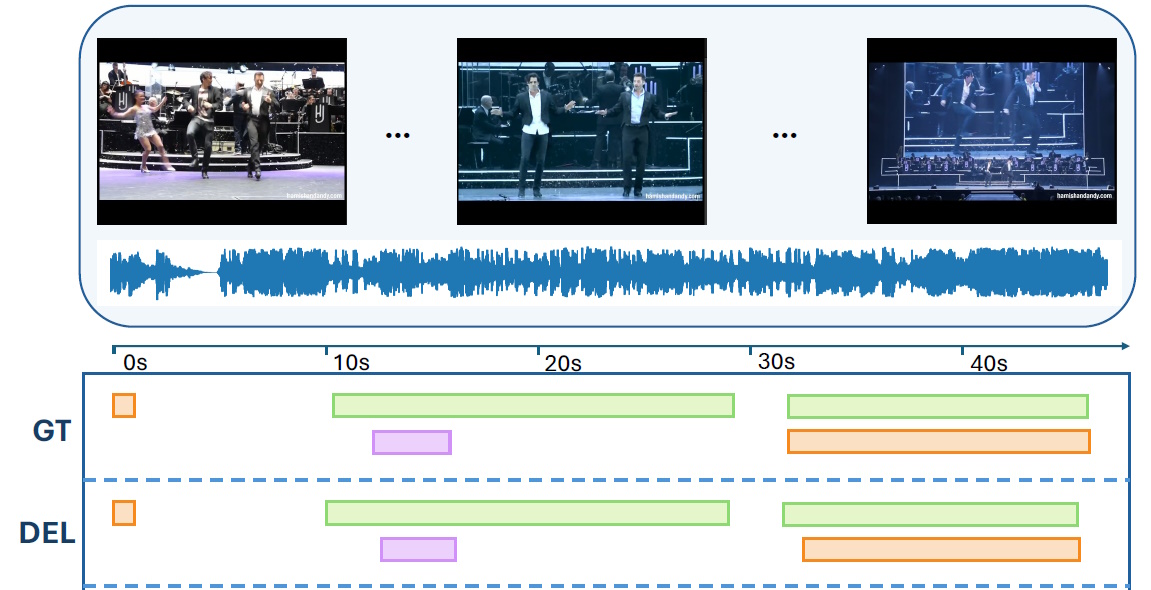
Mona Ahmadian, Amir Shirian, Frank Guerin, Andrew Gilbert, International Confernce on Computer Vision (ICCV’25) - The 4th Workshop on What is Next in Multimodal Foundation Models? (MMFM4) 2025
Multitwine: Multi-Object Compositing with Text and Layout Control

Gemma C Tarrés, Zhe Lin, Zhifei Zhang, He Zhang, Andrew Gilbert, John Collomosse, Soo Ye Kim, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR’25) 2025
Human vs. Machine Minds: Ego-Centric Action Recognition Compared

Sadegh Rahmani, Filip Rybansky, Quoc Vuong, Frank Guerin, Andrew Gilbert, IEEE/CVF Conference on Computer Vision and Pattern Recognition - Workshop on Multimodal Algorithmic Reasoning (MAR’25) , 2025
DANTE-AD: Dual-Vision Attention Network for Long-Term Audio Description
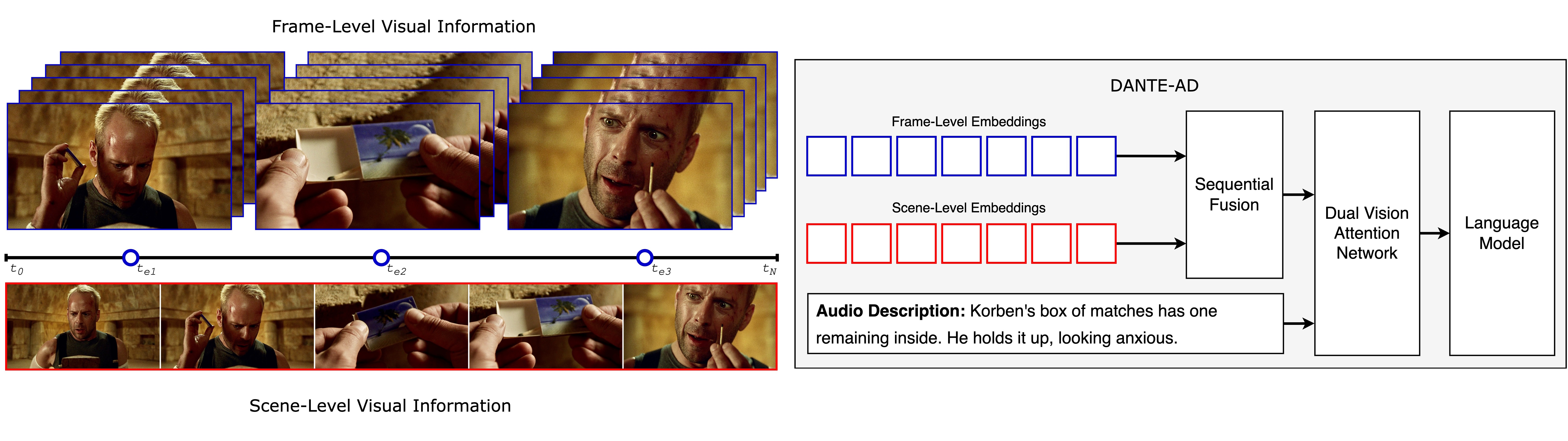
Adrienne Deganutti, Simon Hadfield, Andrew Gilbert, IEEE/CVF Conference on Computer Vision and Pattern Recognition - Workshop on AI for Content Creation Workshop (AICC’25), 2025
Content ARCs: Decentralized Content Rights in the Age of Generative AI
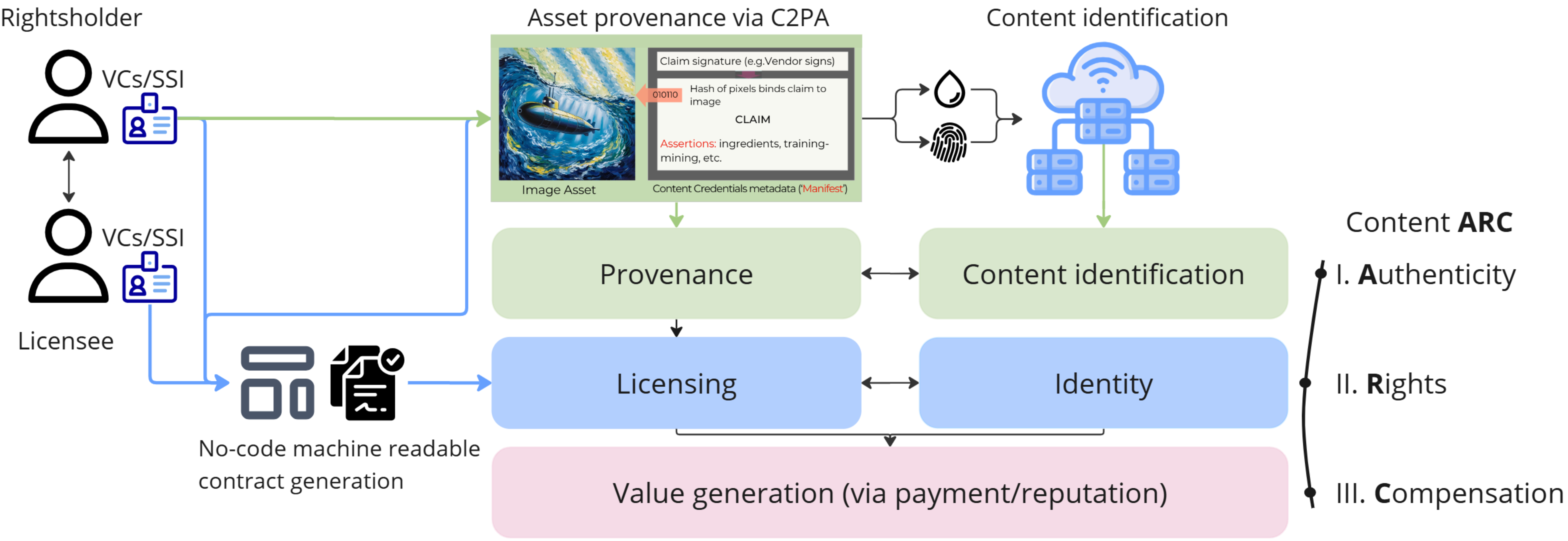
Kar Balan, Andrew Gilbert, John Collomosse, International Conference on AI and the Digital Economy (CADE’25) 2025
MultiNeRF: Multiple Watermark Embedding for Neural Radiance Fields
Yash Kulthe, Andrew Gilbert, John Collomosse, International Conference on Learning Representations (ICLR’25) - The 1st Workshop on GenAI Watermarking, 2025
2024
FILS: Self-Supervised Video Feature Prediction In Semantic Language Space
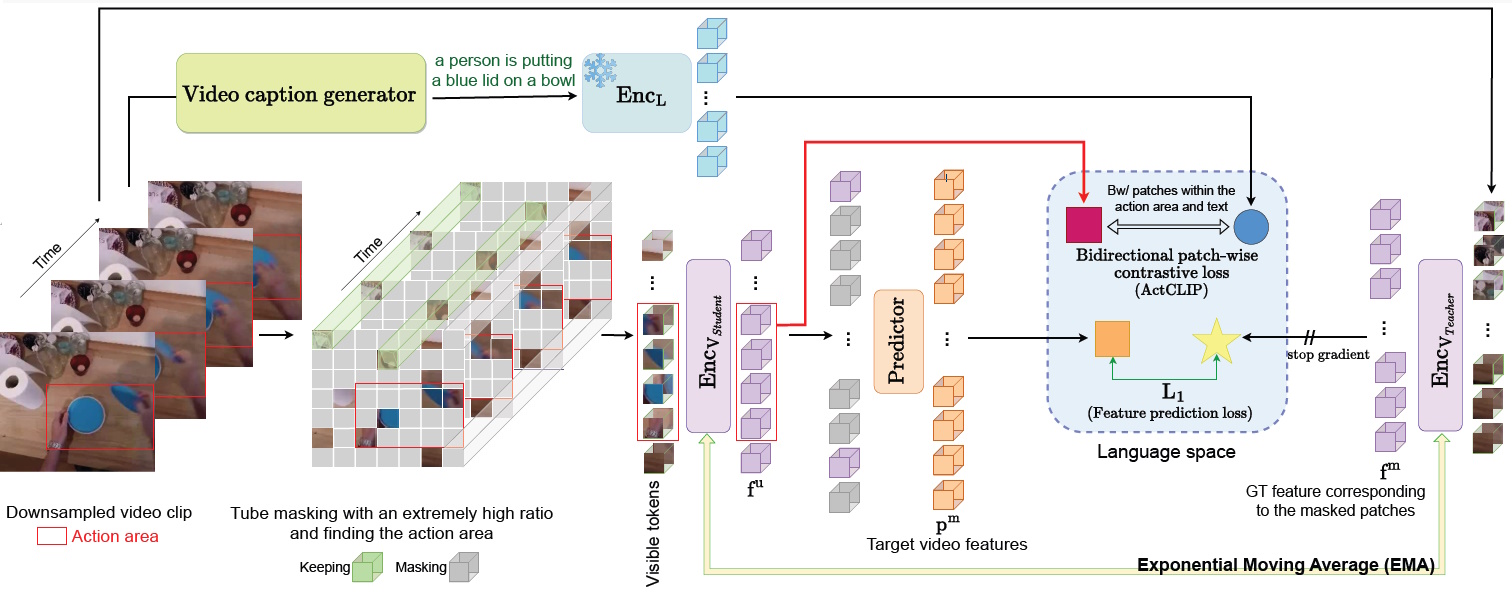
Mona Ahmadian, Frank Guerin, Andrew Gilbert, The 35th British Machine Vision Conference (BMVC’24) 2024
Interpretable Long-term Action Quality Assessment
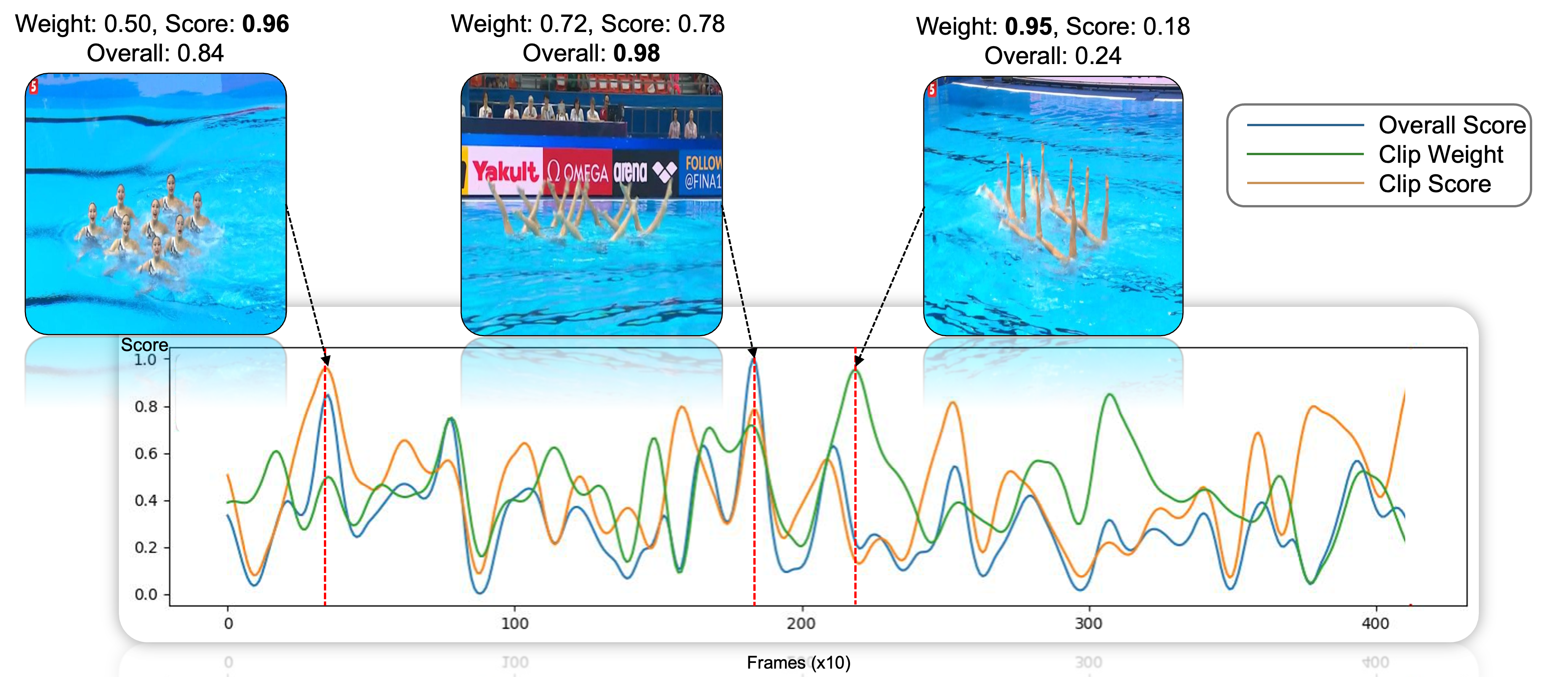
Xu Dong, Xinran Liu, Wanqing Li, Anthony Adeyemi-Ejeye,Andrew Gilbert, The 35th British Machine Vision Conference (BMVC’24) (Oral) 2024
PDFed: Privacy-Preserving and Decentralized Asynchronous Federated Learning for Diffusion Models
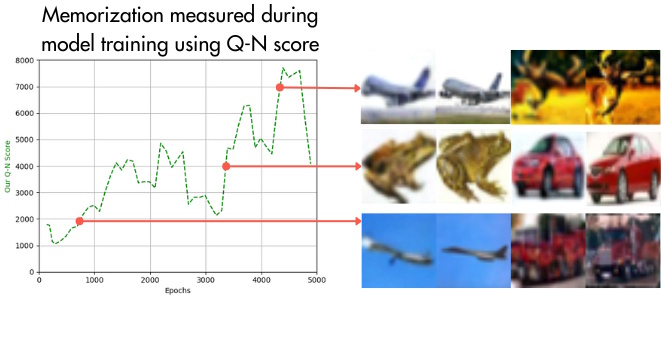
Kar Balan, Andrew Gilbert, John Collomosse, Conference on Visual Media Production (CVMP’24) 2024
Detection and Re-Identification in the case of Horse Racing
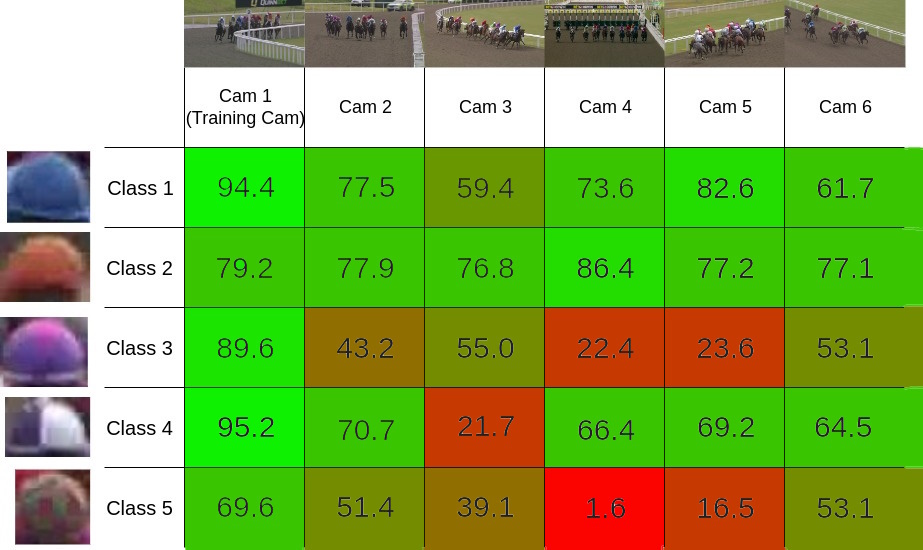
Will Binning, Sadegh Rahmani, Xu Dong, Andrew Gilbert, Conference on Visual Media Production (CVMP’24) 2024
Thinking Outside the BBox: Unconstrained Generative Object Compositing

Gemma C Tarrés, Zhe Lin, Zhifei Zhang, Jianming Zhang, Yizhi Song, Dan Ruta, Andrew Gilbert, John Collomosse, Soo Ye Kim, European Conference on Computer Vision ECCV’24 2024
ViscoNet: Bridging and Harmonizing Visual and Textual Conditioning for ControlNet

Soon Cheong, Armin Mustafa, Andrew Gilbert, European Conference of Computer Vision 2024, FashionAI: Exploring the intersection of Fashion and Artificial Intelligence for reshaping the Industry, 2024
Diff-nst: Diffusion interleaving for deformable neural style transfer

Dan Ruta, Gemma C Tarrés, Andrew Gilbert, Eli Shechtman, Nick Kolkin, John Collomosse, European Conference of Computer Vision 2024, Vision for Art (VISART VII) Workshop, 2024
Aladin-nst: Self-supervised disentangled representation learning of artistic style through neural style transfer
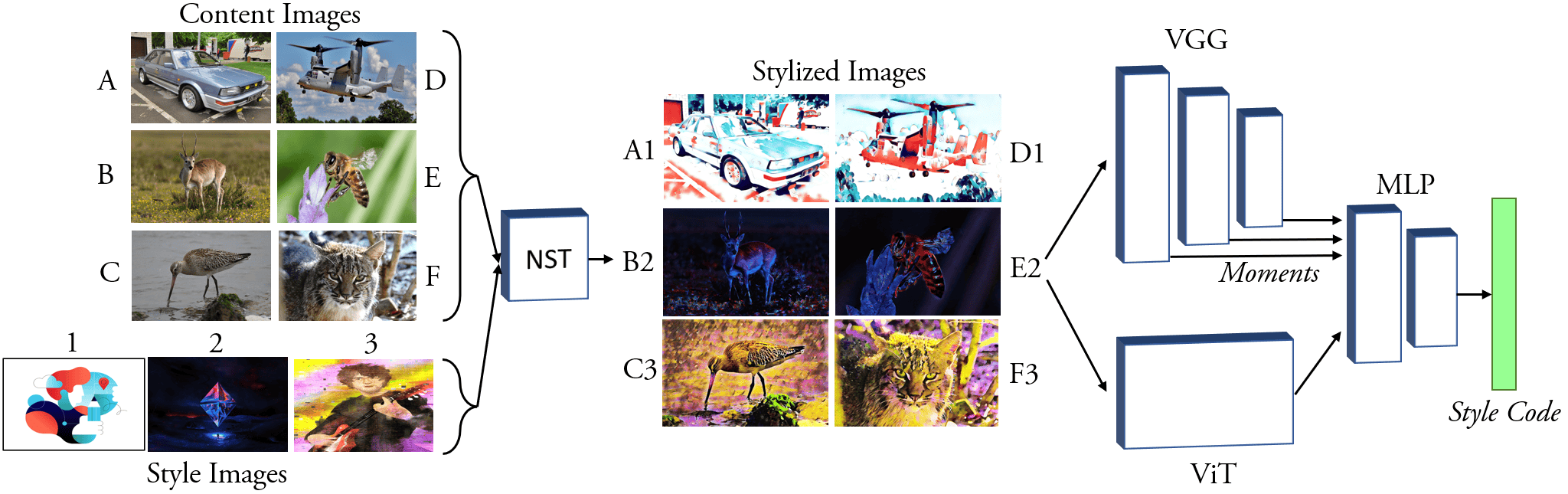
Dan Ruta, Gemma Canet Tarres, Alexander Black, Andrew Gilbert, John Collomosse, European Conference of Computer Vision 2024, Vision for Art (VISART VII) Workshop, 2024
NeAT: Neural Artistic Tracing for Beautiful Style Transfer

Dan Ruta, Andrew Gilbert, John Collomosse, Eli Shechtman, Nicholas Kolkin, European Conference of Computer Vision 2024, Vision for Art (VISART VII) Workshop, 2024
Interpretable Action Recognition on Hard to Classify Actions
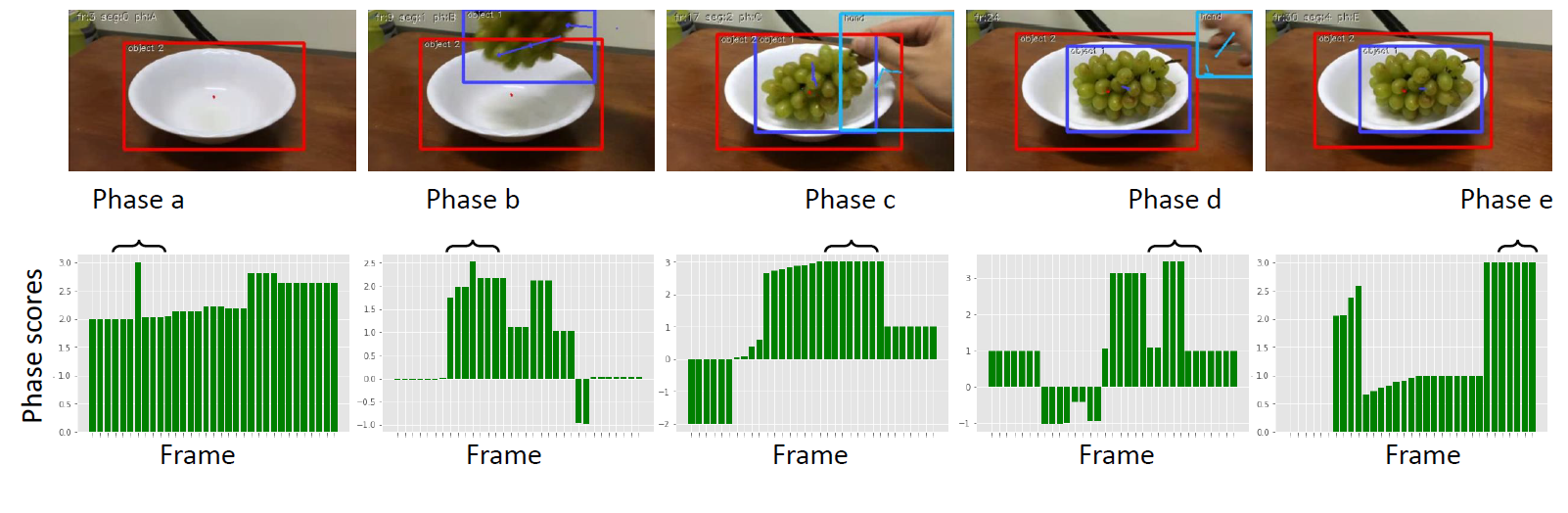
Anastasia Anichenko, Frank Guerin, and Andrew Gilbert, European Conference of Computer Vision 2024, Human-inspired Computer Vision Workshop, 2024
DEAR: Depth-Estimated Action Recognition
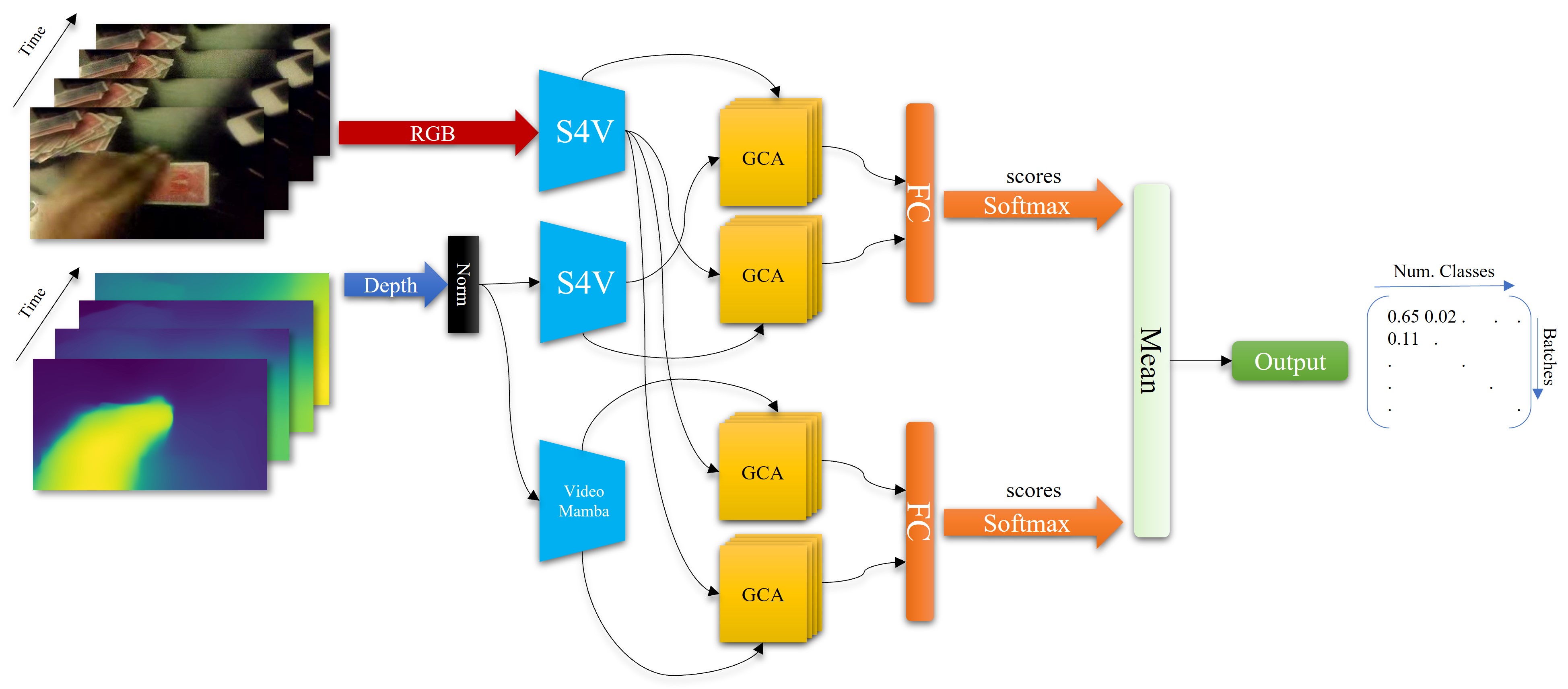
Sadegh Rahmani, Filip Rybansky, Quoc Vuong, Frank Guerin, Andrew Gilbert, European Conference of Computer Vision 2024, Human-inspired Computer Vision Workshop, 2024
Towards Rapid Elephant Flow Detection Using Time Series Prediction for OTT Streaming
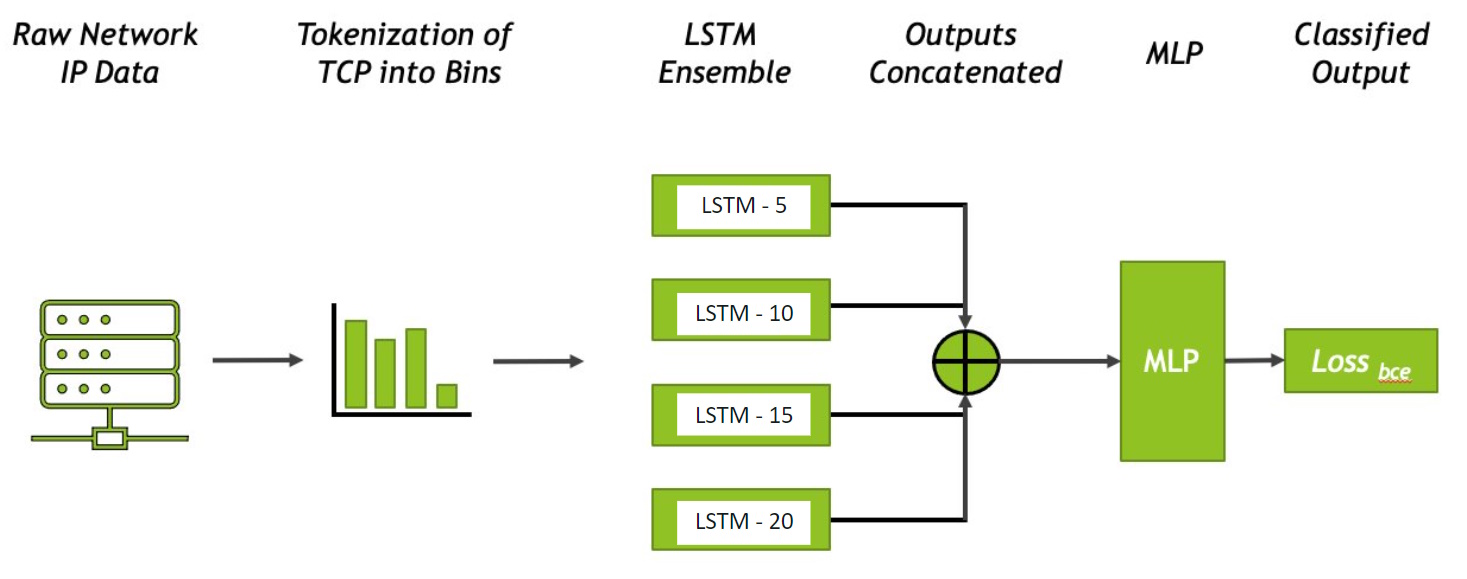
Anthony Orme, Anthony Adeyemi-Ejeye and Gilbert, Andrew, 19th IEEE International Symposium on Broadband Multimedia Systems and Broadcasting BMSB 2024
2023
Multi-Resolution Audio-Visual Feature Fusion for Temporal Action Localization
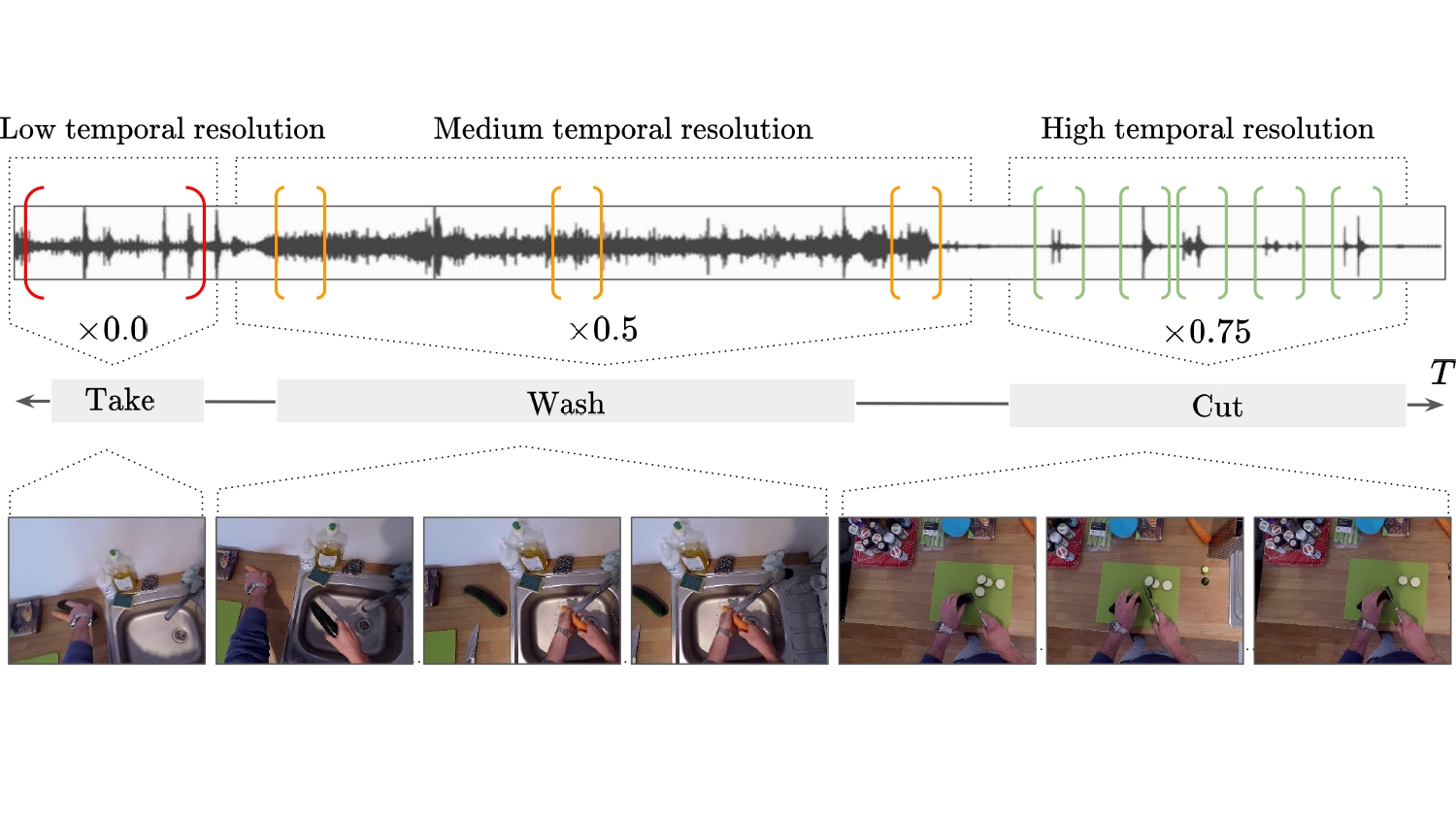
Ed Fish, Jon Weinbren, Andrew Gilbert, NeurIPS 2023 Workshop on Machine Learning for Audio, 2023
MOFO: MOtion FOcused Self-Supervisionfor Video Understanding
Mona Ahmadian, Frank Guerin, Andrew Gilbert, NeurIPS 2023 Workshop Self-Supervised Learning: Theory and Practice, 2023
UPGPT: Universal Diffusion Model for Person Image Generation, Editing and Pose Transfer
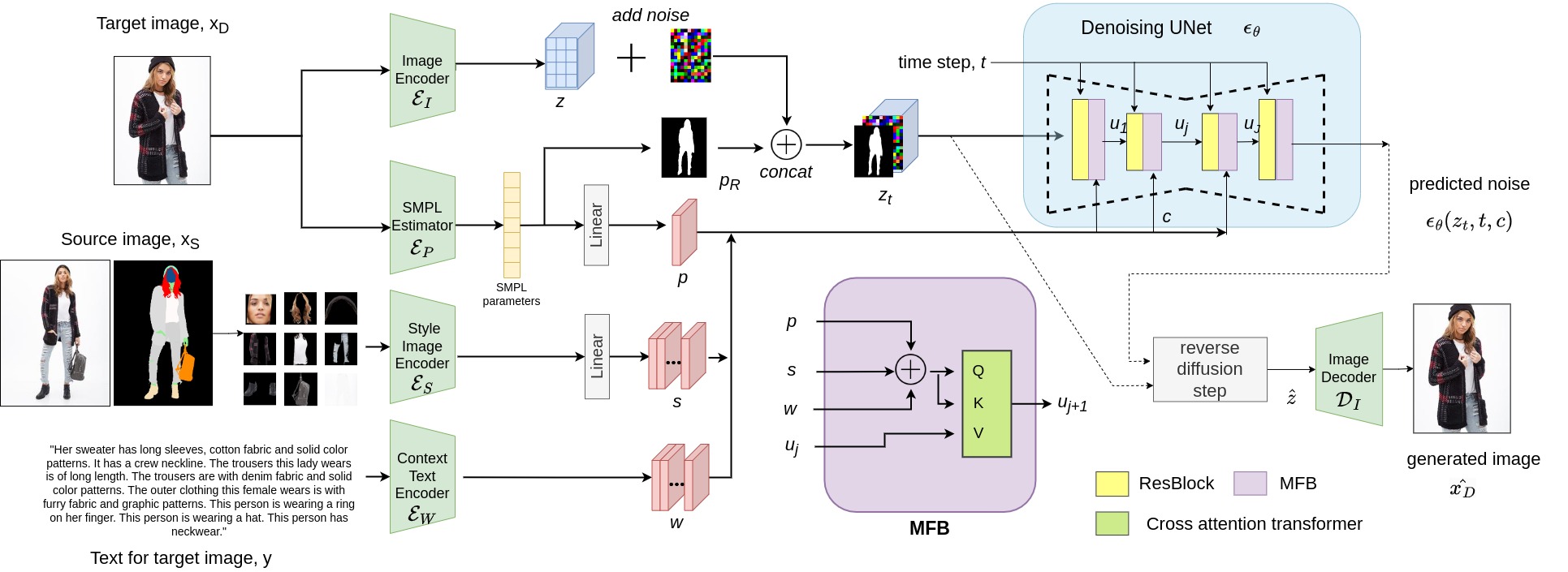
Soon Cheong, Armin Mustafa, Andrew Gilbert, ICCVWS’23 2nd computer vision for Metaverse workshop, 2023
DECORAIT - DECentralized Opt-in/out Registry for AI Training

Kar Balan, Alex Black, Simon Jenni, Andy Parsons, Andrew Gilbert, John Collomosse. The 20th ACM SIGGRAPH European Conference on Visual Media Production (CVMP’23), 2023 - Best Paper
Ekila: synthetic media provenance and attribution for generative art

Kar Balan, Shruti Agarwal, Simon Jenni, Andy Parsons, Andrew Gilbert, John Collomosse, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2023
2022
SVS: Adversarial refinement for sparse novel view synthesis VM González, A Gilbert, G Phillipson, S Jolly, S Hadfield arXiv preprint arXiv:2211.07301 2 2022
Hypernst: Hyper-networks for neural style transfer D Ruta, A Gilbert, S Motiian, B Faieta, Z Lin, J Collomosse European Conference on Computer Vision, 201-217 5 2022
StyleBabel: artistic style tagging and captioning D Ruta, A Gilbert, P Aggarwal, N Marri, A Kale, J Briggs, C Speed, H Jin, … European Conference on Computer Vision, 219-236 9 2022
Two-Stream Transformer Architecture for Long Form Video Understanding E Fish, J Weinbren, A Gilbert British Machine Vision Conference (BMVC) 2022
SaiNet: Stereo aware inpainting behind objects with generative networks VM González, A Gilbert, G Phillipson, S Jolly, S Hadfield arXiv preprint arXiv:2205.07014 1 2022
Kpe: Keypoint pose encoding for transformer-based image generation SY Cheong, A Mustafa, A Gilbert arXiv preprint arXiv:2203.04907 5 2022
2021
Rethinking genre classification with fine grained semantic clustering
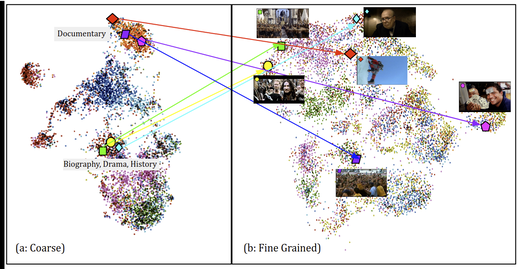
Ed Fish, Jon Weinbren, Andrew Gilbert, IEEE International Conference on Image Processing (ICIP), 2021
Neural architecture search for deep image prior K Ho, A Gilbert, H Jin, J Collomosse Computers & graphics 98, 188-196 37 2021
Human-like Relational Models for Activity Recognition in Video J Chrol-Cannon, A Gilbert, R Lazic, A Madhusoodanan, F Guerin arXiv preprint arXiv:2107.05319 2021
ALADIN: All Layer Adaptive Instance Normalization for Fine-grained Style Similarity D Ruta, S Motiian, B Faieta, Z Lin, H Jin, A Filipkowski, A Gilbert, … arXiv preprint arXiv:2103.09776 23 2021
2019
Semantic estimation of 3d body shape and pose using minimal cameras A Gilbert, M Trumble, A Hilton, J Collomosse arXiv preprint arXiv:1908.03030 1 2019
Fusing visual and inertial sensors with semantics for 3d human pose estimation A Gilbert, M Trumble, C Malleson, A Hilton, J Collomosse International Journal of Computer Vision 127, 381-397 66 2019
Automatic image annotation at ImageCLEF J Wang, A Gilbert, B Thomee, M Villegas Information Retrieval Evaluation in a Changing World: Lessons Learned from … 3 2019
2018
Inpainting of wide-baseline multiple viewpoint video A Gilbert, M Trumble, A Hilton, J Collomosse IEEE Transactions on Visualization and Computer Graphics 26 (7), 2417-2428 4 2018
Deep autoencoder for combined human pose estimation and body model upscaling M Trumble, A Gilbert, A Hilton, J Collomosse Proceedings of the European Conference on Computer Vision (ECCV), 784-800 65 2018
Volumetric performance capture from minimal camera viewpoints A Gilbert, M Volino, J Collomosse, A Hilton Proceedings of the European Conference on Computer Vision (ECCV), 566-581 60 2018
Disentangling structure and aesthetics for style-aware image completion A Gilbert, J Collomosse, H Jin, B Price Proceedings of the IEEE Conference on Computer Vision and Pattern … 15 2018
2017
Total capture: 3d human pose estimation fusing video and inertial sensors
M Trumble, A Gilbert, C Malleson, A Hilton, J Collomosse. Proceedings of 28th British Machine Vision Conference, 1-13 290 2017
Total capture: 3d human pose estimation fusing video and inertial sensors
Image and video mining through online learning A Gilbert, R Bowden Computer Vision and Image Understanding 158, 72-84 10 2017
Guided optimisation through classification and regression for hand pose estimation P Krejov, A Gilbert, R Bowden Computer Vision and Image Understanding 155, 124-138 35 2017
Real-time Full-Body Motion Capture from Video and IMUs C Malleson, A Gilbert, M Trumble, J Collomosse, A Hilton 92 2017
2016
Deep convolutional networks for marker-less human pose estimation from multiple views M Trumble, A Gilbert, A Hilton, J Collomosse Proceedings of the 13th European conference on visual media production (CVMP … 22 2016
Overview of the ImageCLEF 2016 Scalable Concept Image Annotation Task. A Gilbert, L Piras, J Wang, F Yan, A Ramisa, E Dellandrea, … CLEF (Working Notes), 254-278 24 2016
Learning Markerless human pose estimation from multiple viewpoint video M Trumble, A Gilbert, A Hilton, J Collomosse Computer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8 … 4 2016
Learning multi-class discriminative patterns using episode-trees RB Eng Jon Ong, Nicolas Pugeault, Andrew Gilbert IARIA 2016
2015
Geometric Mining: Scaling Geometric Hashing to Large Datasets A Gilbert, R Bowden 3rd Workshop on Web-scale Vision and Social Media (VSM), at ICCV 2015 2 2015
Overview of the ImageCLEF 2015 Scalable Image Annotation, Localization and Sentence Generation task. A Gilbert, L Piras, J Wang, F Yan, E Dellandrea, RJ Gaizauskas, … CLEF (Working Notes) 39 2015
Combining discriminative and model based approaches for hand pose estimation P Krejov, A Gilbert, R Bowden 2015 11th IEEE international conference and workshops on automatic face and … 34 2015
Data mining for action recognition A Gilbert, R Bowden Computer Vision–ACCV 2014: 12th Asian Conference on Computer Vision … 5 2015
General overview of ImageCLEF at the CLEF 2015 labs M Villegas, H Müller, A Gilbert, L Piras, J Wang, K Mikolajczyk, … Experimental IR Meets Multilinguality, Multimodality, and Interaction: 6th … 109 2015
2014
Capturing relative motion and finding modes for action recognition in the wild O Oshin, A Gilbert, R Bowden Computer Vision and Image Understanding 125, 155-171 17 2014
A multitouchless interface: expanding user interaction P Krejov, A Gilbert, R Bowden IEEE computer graphics and applications 34 (3), 40-48 8 2014
2012
Meeting in the Middle: A top-down and bottom-up approach to detect pedestrians A Shaukat, A Gilbert, D Windridge, R Bowden Proceedings of the 21st International Conference on Pattern Recognition … 3 2012
A picture is worth a thousand tags: automatic web based image tag expansion A Gilbert, R Bowden Asian Conference on Computer Vision, 447-460 10 2012
Data fusion in ubiquitous networked robot systems for urban services L Merino, A Gilbert, J Capitán, R Bowden, J Illingworth, A Ollero annals of telecommunications-annales des télécommunications 67, 355-375 15 2012
2011
igroup: Weakly supervised image and video grouping A Gilbert, R Bowden 2011 International Conference on Computer Vision, 2166-2173 10 2011
Push and Pull: Iterative grouping of media A Gilbert, R Bowden British Machine Vision Conference 2011 2 2011
There is more than one way to get out of a car: Automatic Mode Finding for Action Recognition in the Wild O Oshin, A Gilbert, R Bowden Iberian Conference on Pattern Recognition and Image Analysis, 41-48 2011
Visualisation and prediction of conversation interest through mined social signals D Okwechime, EJ Ong, A Gilbert, R Bowden 2011 IEEE International Conference on Automatic Face & Gesture Recognition … 6 2011
Capturing the relative distribution of features for action recognition O Oshin, A Gilbert, R Bowden 2011 IEEE International Conference on Automatic Face & Gesture Recognition … 31 2011
Social interactive human video synthesis D Okwechime, EJ Ong, A Gilbert, R Bowden Computer Vision–ACCV 2010: 10th Asian Conference on Computer Vision … 6 2011
2010
Action recognition using mined hierarchical compound features A Gilbert, J Illingworth, R Bowden IEEE Transactions on Pattern Analysis and Machine Intelligence 33 (5), 883-897 231 2010
Decentralized sensor fusion for ubiquitous networking robotics in urban areas A Sanfeliu, J Andrade-Cetto, M Barbosa, R Bowden, J Capitán, … Sensors 10 (3), 2274-2314 60 2010
Learning to recognise spatio-temporal interest points OT Oshin, A Gilbert, J Illingworth, R Bowden Machine Learning for Human Motion Analysis: Theory and Practice, 14-30 1 2010
2009
Fast realistic multi-action recognition using mined dense spatio-temporal features A Gilbert, J Illingworth, R Bowden 2009 IEEE 12th international conference on computer vision, 925-931 226 2009
Accurate fusion of robot, camera and wireless sensors for surveillance applications A Gilbert, J Illingworth, R Bowden, J Capitan, L Merino 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV … 7 2009
Action recognition using randomised ferns O Oshin, A Gilbert, J Illingworth, R Bowden 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV … 26 2009
2008
Scalable and Adaptable Tracking of Humans in Multiple Camera Systems

Doctoral Thesis for Phd in Computer Vision of Andrew Gilbert, University of Surrey, 2008
Incremental, scalable tracking of objects inter camera A Gilbert, R Bowden Computer Vision and Image Understanding 111 (1), 43-58 54 2008
Scalable and adaptable tracking of humans in multiple camera systems A Gilbert PQDT-UK & Ireland 3 2008
Scale invariant action recognition using compound features mined from dense spatio-temporal corners A Gilbert, J Illingworth, R Bowden Computer Vision–ECCV 2008: 10th European Conference on Computer Vision … 136 2008
2006
Tracking objects across uncalibrated arbitrary topology camera networks R Bowden, A Gilbert, P KaewTraKulPong Intelligent Distributed Video Surveillance Systems, 157-182 6 2006
Poster Session II-Tracking and Motion-Tracking Objects Across Cameras by Incrementally Learning Inter-camera Colour Calibration and Patterns of Activity A Gilbert, R Bowden Lecture Notes in Computer Science 3952, 125-136 2006
Tracking objects across cameras by incrementally learning inter-camera colour calibration and patterns of activity A Gilbert, R Bowden Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz …